Probabilistic Memory Retrieval
A proof of concept in probabilistic retrival of memory using neural networks.
Introduction
This idea came into existance after reading the article written by Jay Alammar on RETRO model The Illustrated Retrieval Transformer. Its a small but intuitively written post about RETRO model and how it work. Its highly recommend that you read it before continuing this post.
Basic idea of retro model can be summarized into 5 steps
- Get a text query.
- Pass the query to a pre-trained model like BERT which ouptut its embeddings.
- This embedding vector is used for fetching 'n' number of similar/neigbour textual chunks from a key-value database.
- The retrieved 'n' textual chunks were used to train the RETRO model.
- The trained RETRO model along with the BERT is used to predict the answers.
Hypothesis/Idea
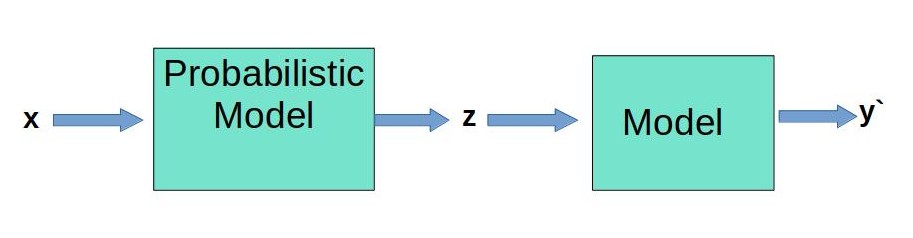
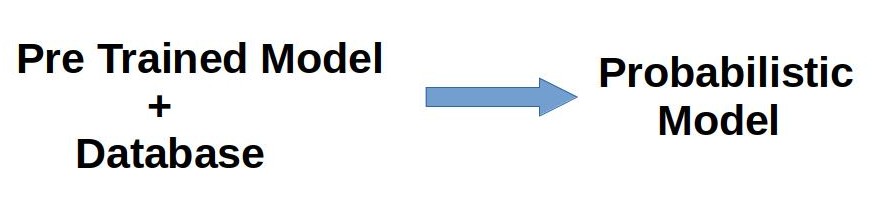
In the original RETRO paper the authors have used BERT+DATBASE to retrieve additonal information, that is, step:1 - step:3 to train a RETRO model. My idea is to combine the step:1 through step:3 and approximate it into a probabilistic model. Instead of retriving similar/neigbour chunks from database we sample from this probabilistic model to get similar/neigbouring low dimensional latent vectors. We then use this latent vectors to train a RETRO like MLP model. The idea is, the probabilistic model will act like a memory reservoir for storing data and the MLP will fetch additional data from this reservoir to predict an output. The assumption is that instead of using a single input the additonal retrived neigbouring vectors will help the model to give more generalized/accurate output without using a large database.
Building probablisitc memory retrieval model
The orginal RETRO paper was trained in textual data. Because of contstraint in resources we opted to use MNIST image data to train this memory retriving plus classification model. In this project a Variational AutoEncoder (VAE) was chosen as the probabilistic model,other probabilistic model should also work given we can sample some latent vectors. The VAE model was not built by myself, I have used Jackson Kang's VAE Model with slight modifications in latent diminesion.
Model training
First the VAE was pre-trained with MNIST
data.From this pre-trained VAE model; for
an image we can fetch its mean and variance
from encoder. Using this mean and variance
we can sample 'n' latent vectors(ours n=10)
using the below formula, here N is the
Normal Distribution. For calculating latent
vectors; mean vector was multiplied with an
alpha (N(1,0.5)), this was done to add
stochasticity inorder to sample from
neigbouring vectors. 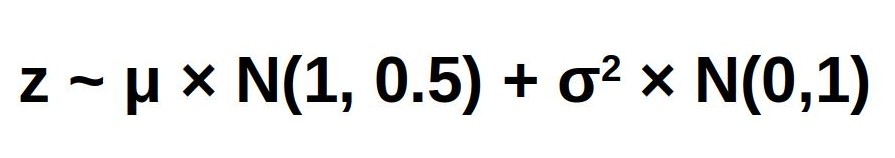 The 'n' latent
vectors generated were used as an input to
train a MLP classifer. We have used latent
vectors to train the MLP instead of the
generated images from VAE due of its lesser
number of dimensions. The lower dimensional
latent vector encodes the important
features and it also helps in faster
training and inference. Another
hypothetical reason for choosing the latent
vector is that we beileve brain encodes and
stores informations in smaller dimensions.
Everyday, Everytime human brain is
bombarded with signals from various analog
sensory inputs such eye, ear, skin etc.
Human brain is a finite storarge machine
and it will unlikely store all these higher
dimensonal inputs from these sensors as raw
data. Its more advantageous to store
memories in lower dimensions and retrieve
those memories probablistically.
The 'n' latent
vectors generated were used as an input to
train a MLP classifer. We have used latent
vectors to train the MLP instead of the
generated images from VAE due of its lesser
number of dimensions. The lower dimensional
latent vector encodes the important
features and it also helps in faster
training and inference. Another
hypothetical reason for choosing the latent
vector is that we beileve brain encodes and
stores informations in smaller dimensions.
Everyday, Everytime human brain is
bombarded with signals from various analog
sensory inputs such eye, ear, skin etc.
Human brain is a finite storarge machine
and it will unlikely store all these higher
dimensonal inputs from these sensors as raw
data. Its more advantageous to store
memories in lower dimensions and retrieve
those memories probablistically.
Result
For a batch size of 1, this model was trained in pytorch with SGD as optimizer and CrossEntropy as loss function.I have trained it for 3 epochs using MNIST full data and the last results are.
- Training Accuracy: 74%
- Testing Accuracy: 73%
Project Github Page: https://github.com/Gananath/probablistic_memory_retrieval